The Summary of Machine learning (StatQuest)
cross validation
sensitivity:the TP(true positive) were correctly identified by the model. TP/(TP+FN)
specificity:the TN(true negative) were correctly identified by the model. TN/(TN+FP)
bias & variance : overfit
3 commonly model: regularization, boosting, and bagging(random forest)
ROC (FPR,TPR): to choose the optimal threshold. higher y, lower x.
AUC (ROC下面积): to choose the model. ROC与x轴围成的面积,越大越好
precision=TP/(TP+FP) [研究罕见病时使用,因为此时TN多
calculate AUC
code from StatQuestpar(pty = "s") #make the plot as a square
Entropy:value of surprise
mutual information; joint probility; marginal probility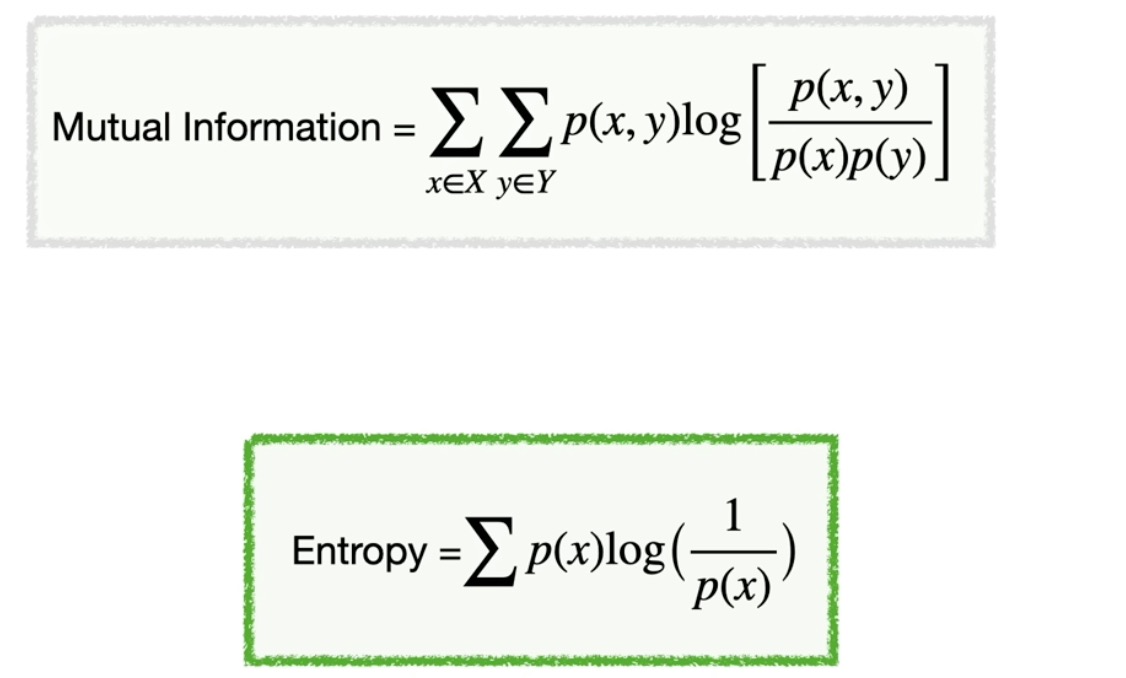
design matrix
combine t-test with regression (F-test)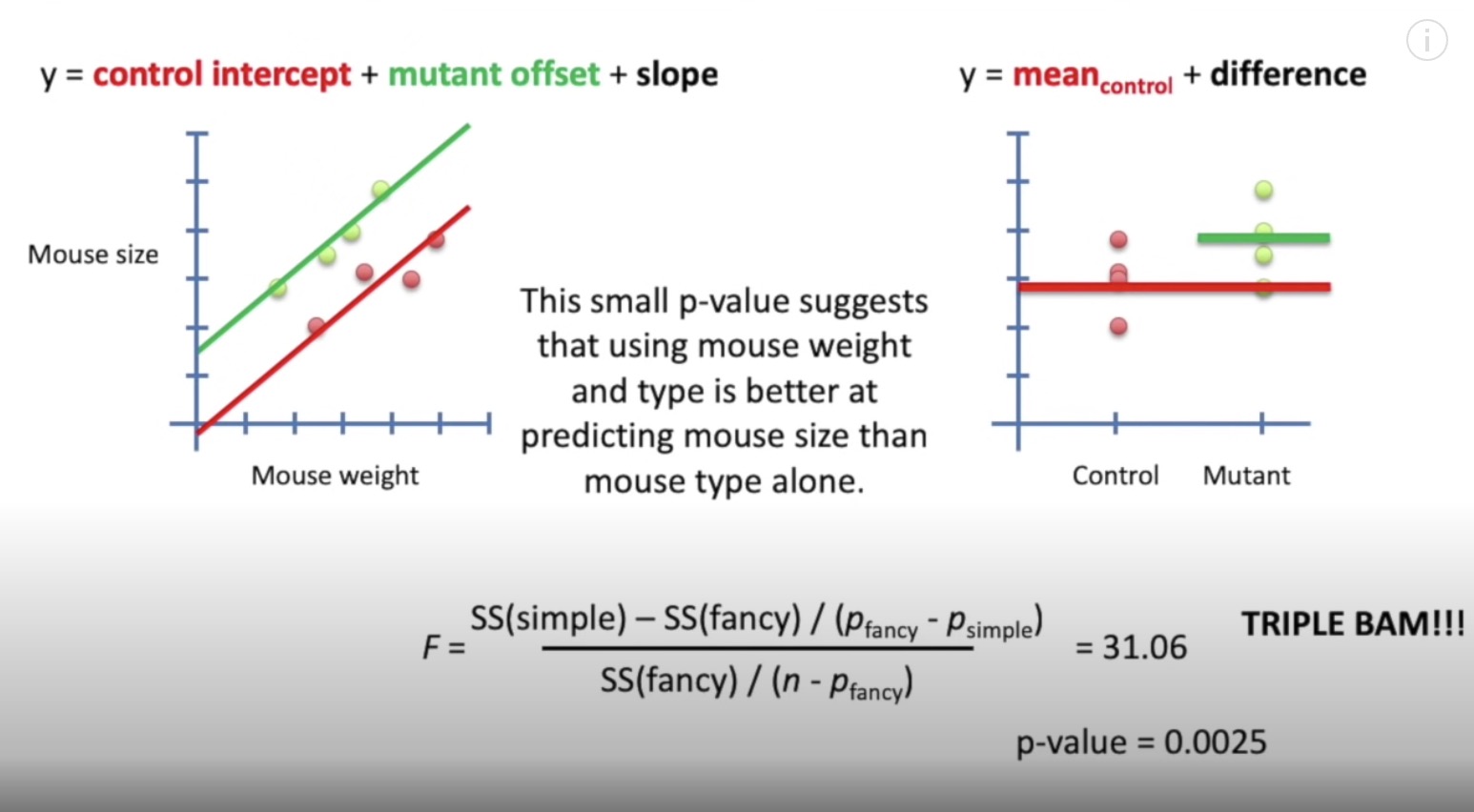
batch effect correct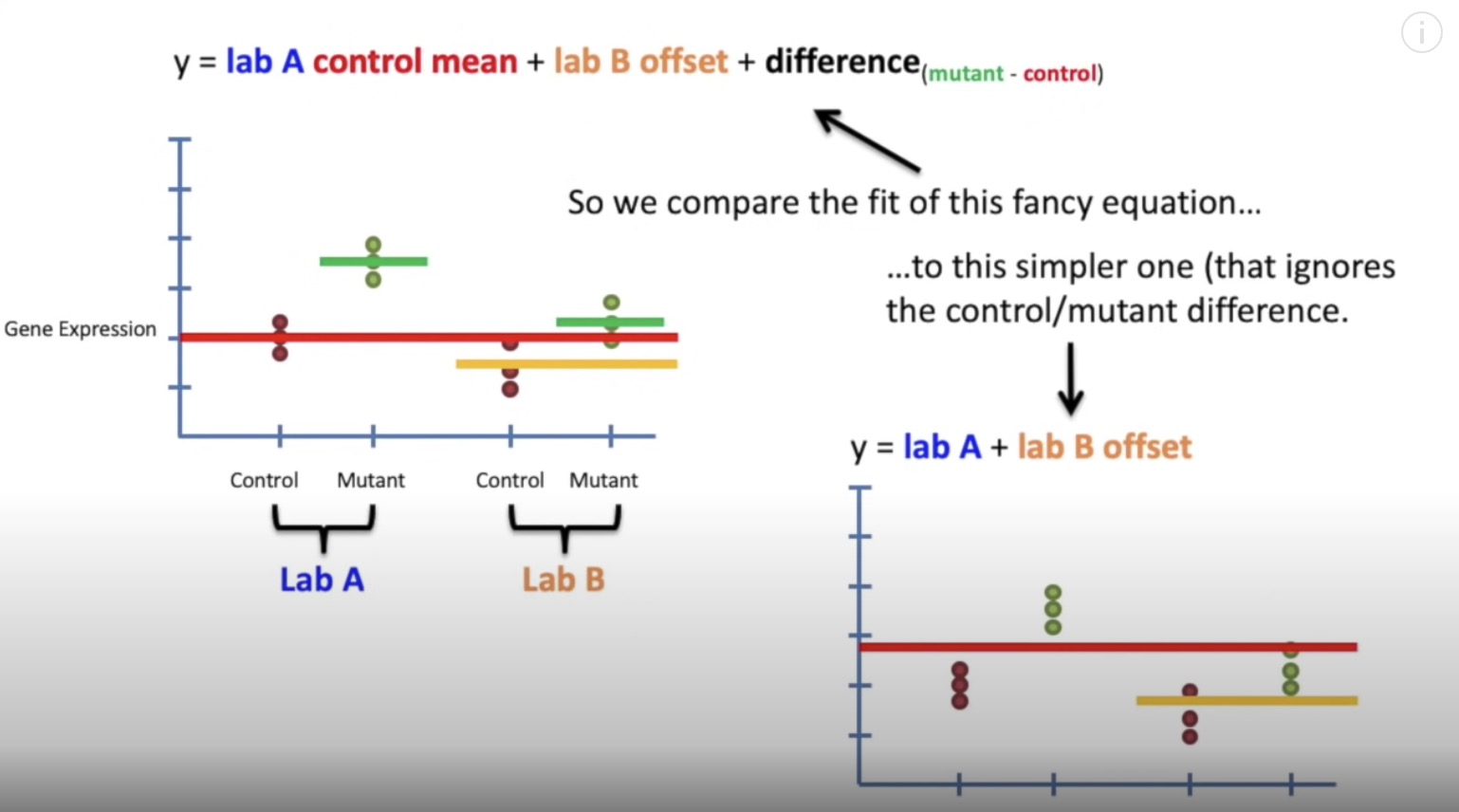
odd and odd ratio
3 ways to determine if an odds ratio is statistically significant.
1)Fisher’s Exact Test
2)Chi-Square Test
3)The Wald Test
coeffecient of logistic regression
?why the standard deviation is calculated by these
and how to calculate the standard error and z-value(=Etimate/standard error.by wald test.it’s the number of standard deviations the estimated intercept is away from 0 on a standard normal curve)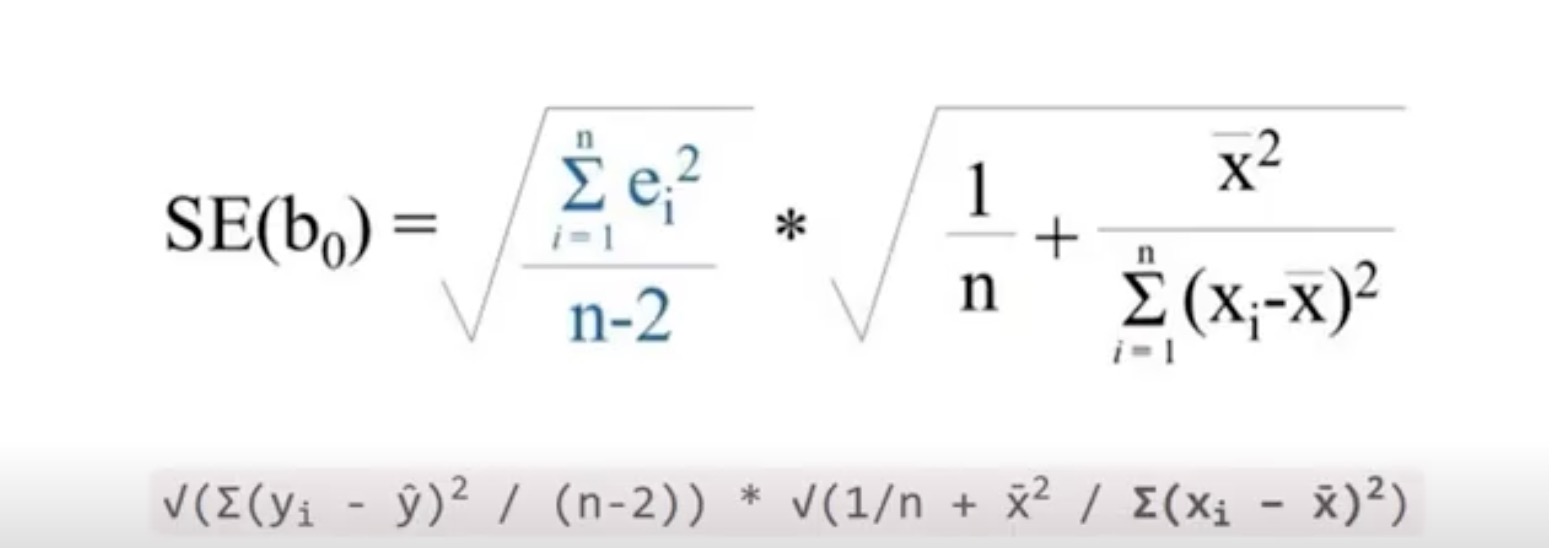
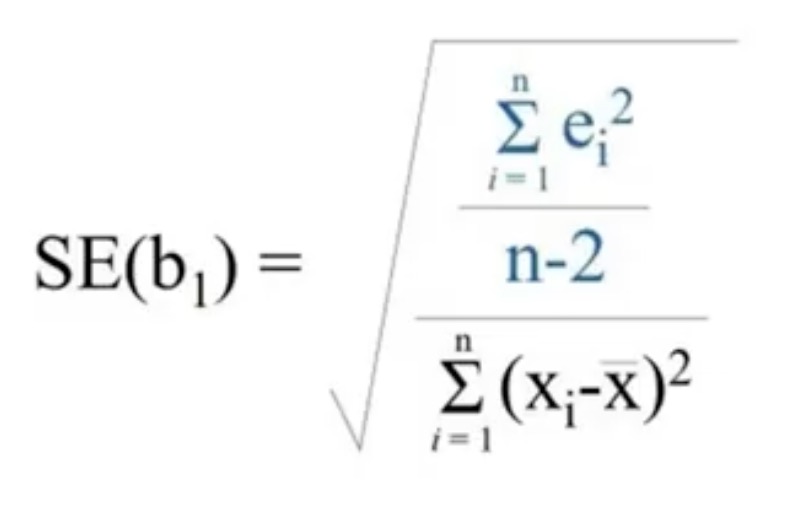
R square and p-value of logistic regression
log-likelihood based R square (aka McFadden’s Pseudo R square)
Saturated Model and Deviance
LL(Saturated model)always=0 because the saturated model fit the spot well.

AIC: Akaike Information Criterion. Residual adjusted for the number of parameters. can be used to compare one model to another.
logistic regression code
1 | # chi-square value = 2*(LL(Proposed) - LL(Null)) |
and predict.
Deviance residuals
the square root of the contribution that each data point has to the overall Residual Deviance. used to identify outliers.
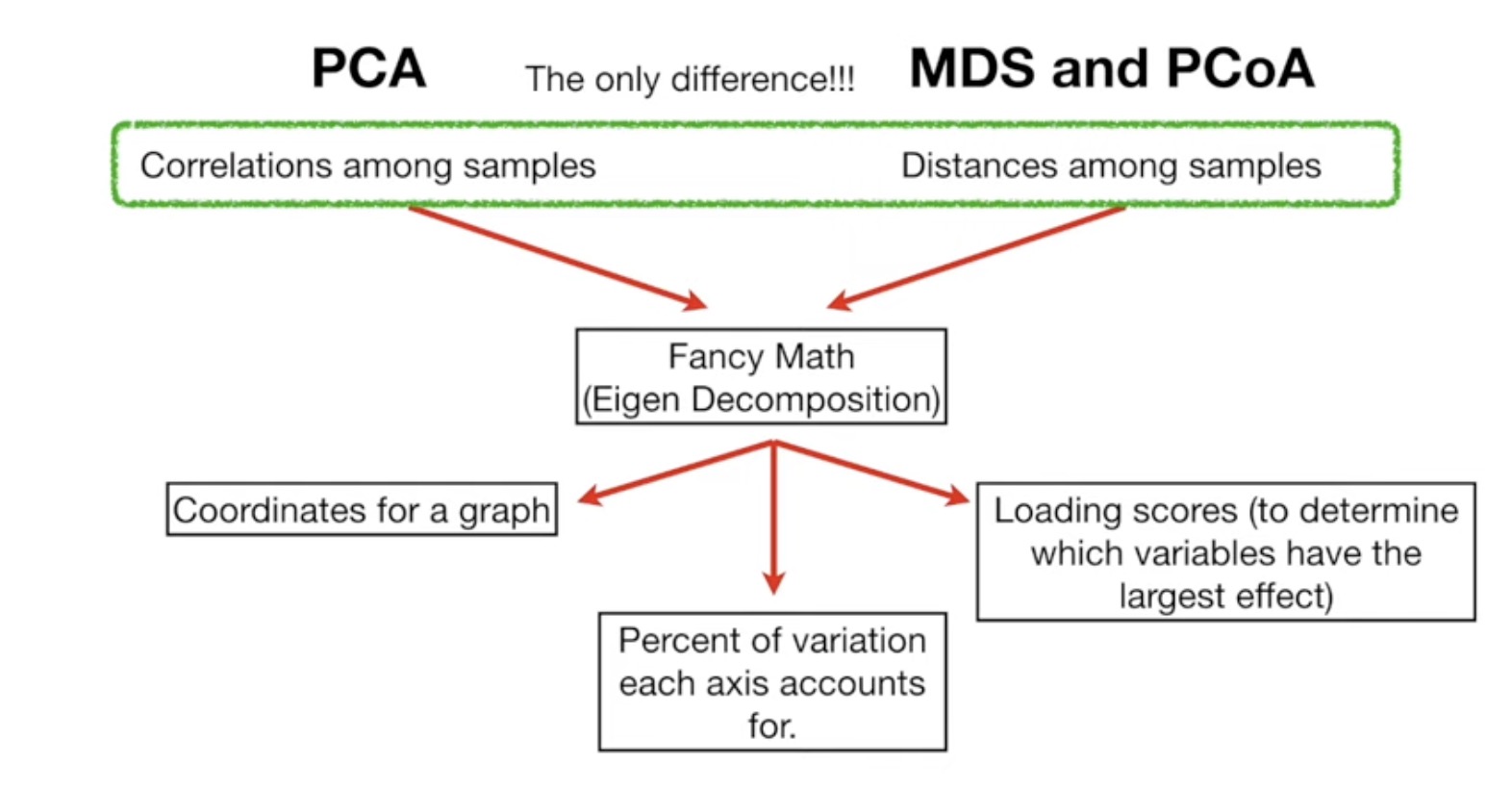
PCA
using SVD(singular value decomposition)
singular vector/eigenvector
loading scores
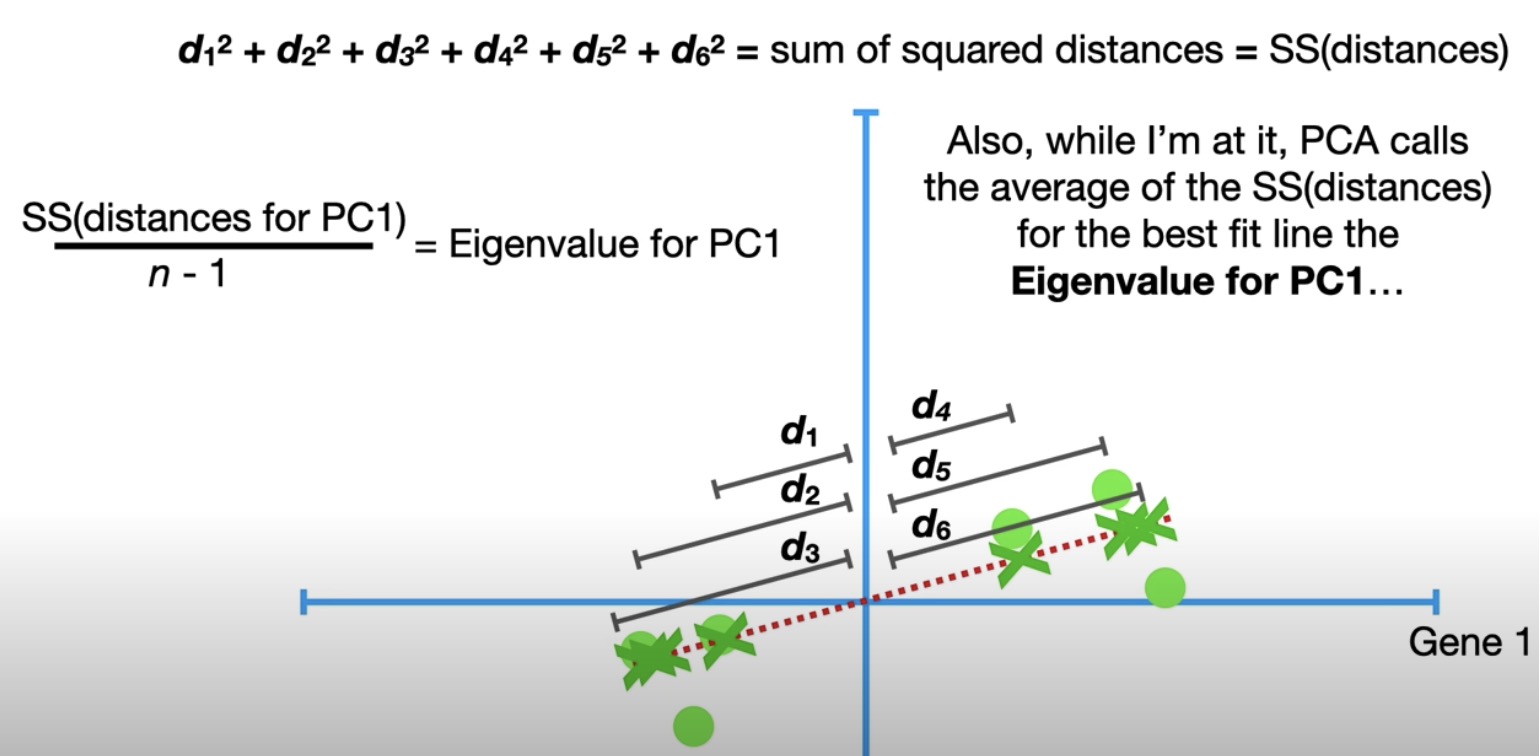
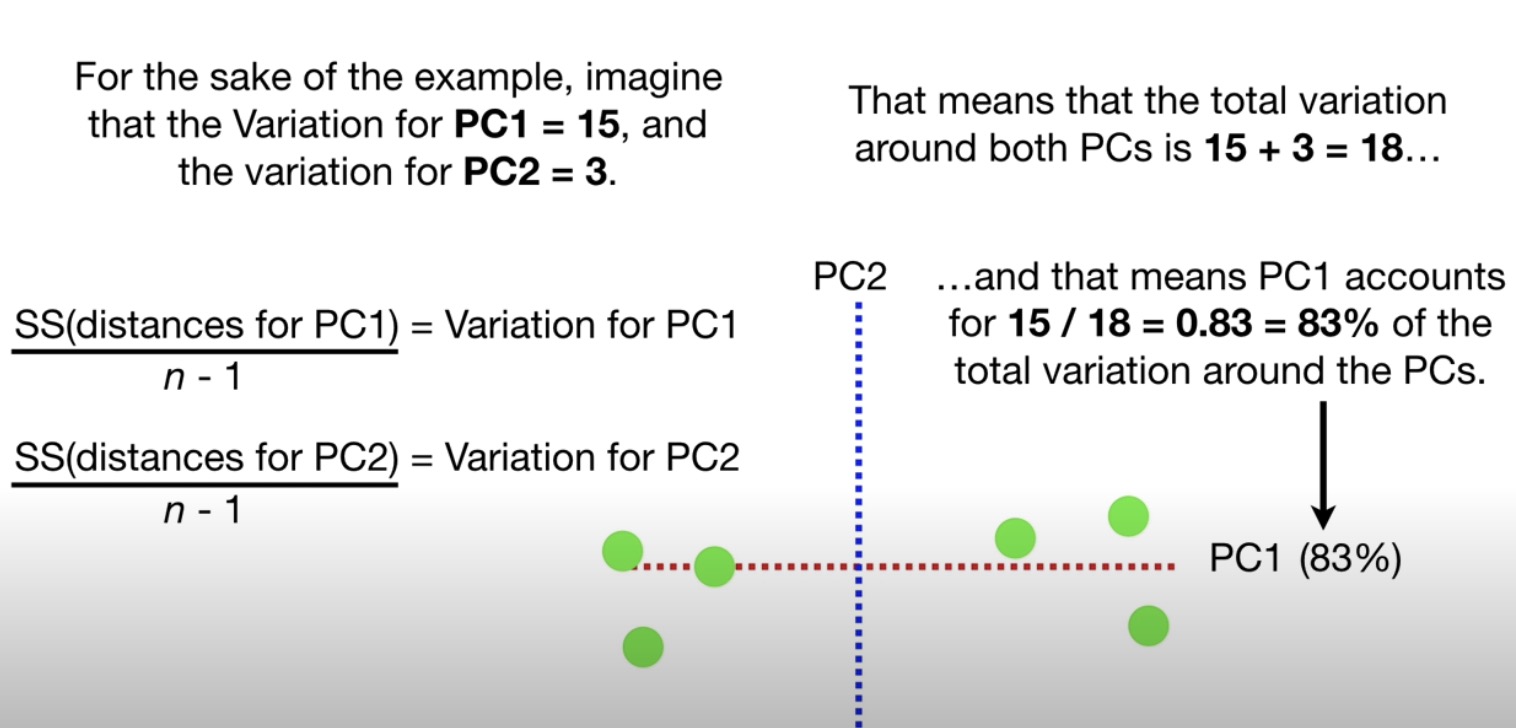
eigenvalue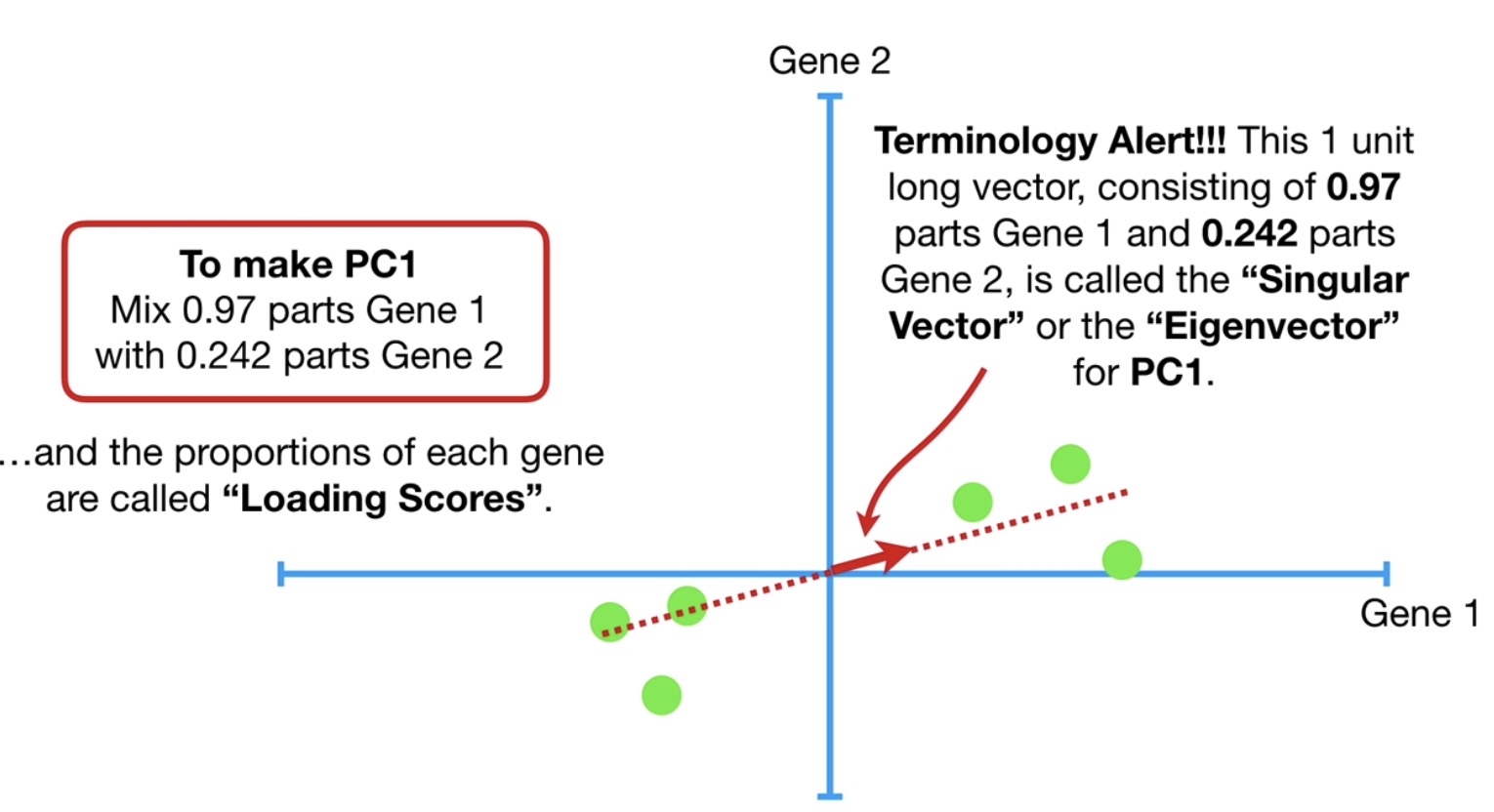
Tips:scaling,centering,and verify the number of principal components.
code in R
note: prcomp require samples on rows. square pca$sdev can be used for %(eigenvector). rotation = loading scores
code in pythonStandardScaler().fit_transform(data.T)
LDA
maximizing the seperatibility between 2 groups while PCA by focusing on the genes with the most variation.
2 criteria: Maximize the distance between means; minimize the variation (scatter;square s)within each category.
MDS and PCoA
1 | dist() |
t-SNE
Hierarchical Clustering
similarity(distance) to form clusters;
decide how to compare sub-clusters:
centroid
single-linkage
complete-linkage;
height of the branches in the ‘dendrogram’ shows what is most similar.
k-means clustering
elbow plot to find ‘K’
DBSCAN
radius of circle for a initial cluster
core point
K-nearest neighbors
Naive Bayes
- Multinomial Naive Bayes Classifier
probability for discrete called likelihood
set alpha to avoid 0
high bia and low variance in ML - Gaussian Naive Bayes Classification
use log() to avoid ‘uderflow’
Decision and Classification tree
test leaves impure: gini impurity, entropy and information gain.
how to calculate gini impurity:
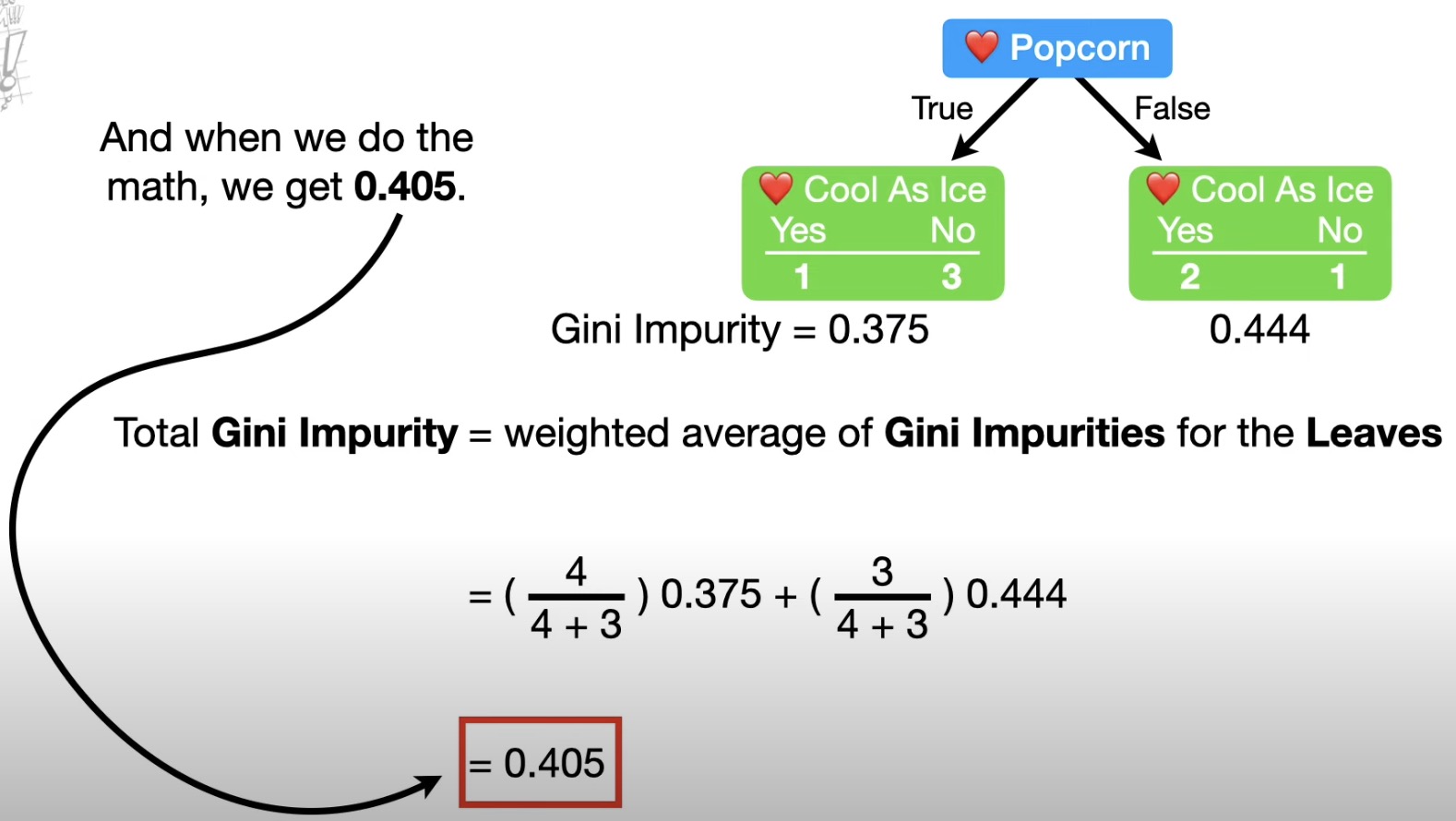
to calculate for numeric data, using average age for all adjacent people.
put lowest impurity leaves as node.
overfit if sample too small -> pruning
or -> put limits on how trees grow(i.e. require x samples per leaf, x is determined by cross varidation)
feature selection: cut off the feature not reduce the impurity to avoid overfit.
Regression trees
determine thresholds by calculating the sum of squared residual, pick up the smallest one.
prune regression tree:
cost complexity pruning(aka weakest link pruning)
– tree score = SSR + alpha * T
(T represent the total number of leaves; alpha T = tree complexity panelty)
– set which alpha gave us the lowest sum of squared ressiduals with the testing data;tree built by full data(train + test)
? what is new training data and testing data
Encoding
one-hot encoding: each discrete option as a colname.
label encoding: as 1,2,3 but not good for meaning.
target encoding: mean for each discrete option.
less samples less confidence.
so Baysian Mean Encoding (aka target encoding, the equation in below picture)
setting m =2 means we need at least 3 rows of data before the option mean, the mean we calculated for blue, becomes more important than the overall mean.
data leakage -> overfit
so k-fold Target encoding turn discrete to continuous variable.
leave-one-out-target encoding
Classification Trees in Python from Start to Finish. code & tutorial
random forest
bootstrapping the data plus using the aggregate to make a decision is called bagging.
out-of-bag dataset used to measure accuracy.
out-of-bag error:the proportion of incorrect classified.
- fill-in missing values
proximity matrix: the time of/ trees number
– orifinal dataset :for dicrete item: the weighted frequency for ‘yes’ is the frequency of ‘yes’ * the weight for ‘yes’
the weight for ‘yes’= proximity of ‘yes’/all proximities
iterative
distance= 1-proximity value ->heatmap/MDS
– new sample: for dicrete item :guess each result and option, then iterative calculate, choose the most correct option, finally fill-in the data and classify the sample.
code
##mtry
loss function
fix slope to find optimal intercept.
the chain rule (拆分求导)
sum of the squaired residuals is a type of loss function.
gradient descent
for LR: step size = slope * learning rates (minimum = 0.001)
note: the results is sensitive to learning rates,the way we change lr is called schedule.
- new intercept = old intercept - step size
(also can be used to find both optimal slope and intercept)
stochastic gradient descent which select subset of data rather than full dataset.
using 1 or mini-batch of samples for each step. easily update the parameters when add new data.
can be used to logistic regression and t-sne.
AdaBoost
(stumps is a node with 2 leaves.)
Amount of Say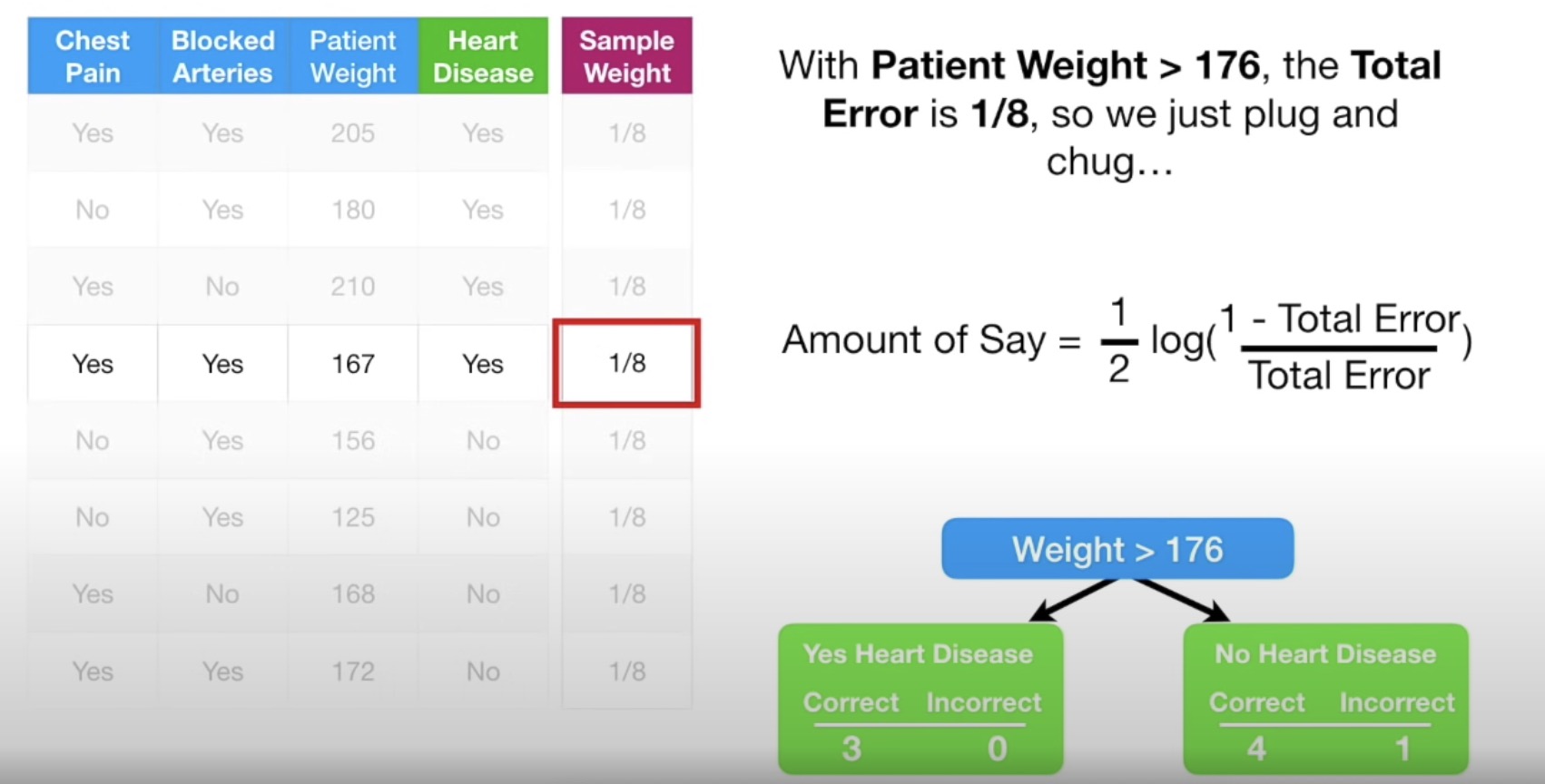
Weighted Gini Function -> sample weights
Gradient Boost
- Gradient Boost for Regression is different from doing Linear Regression.
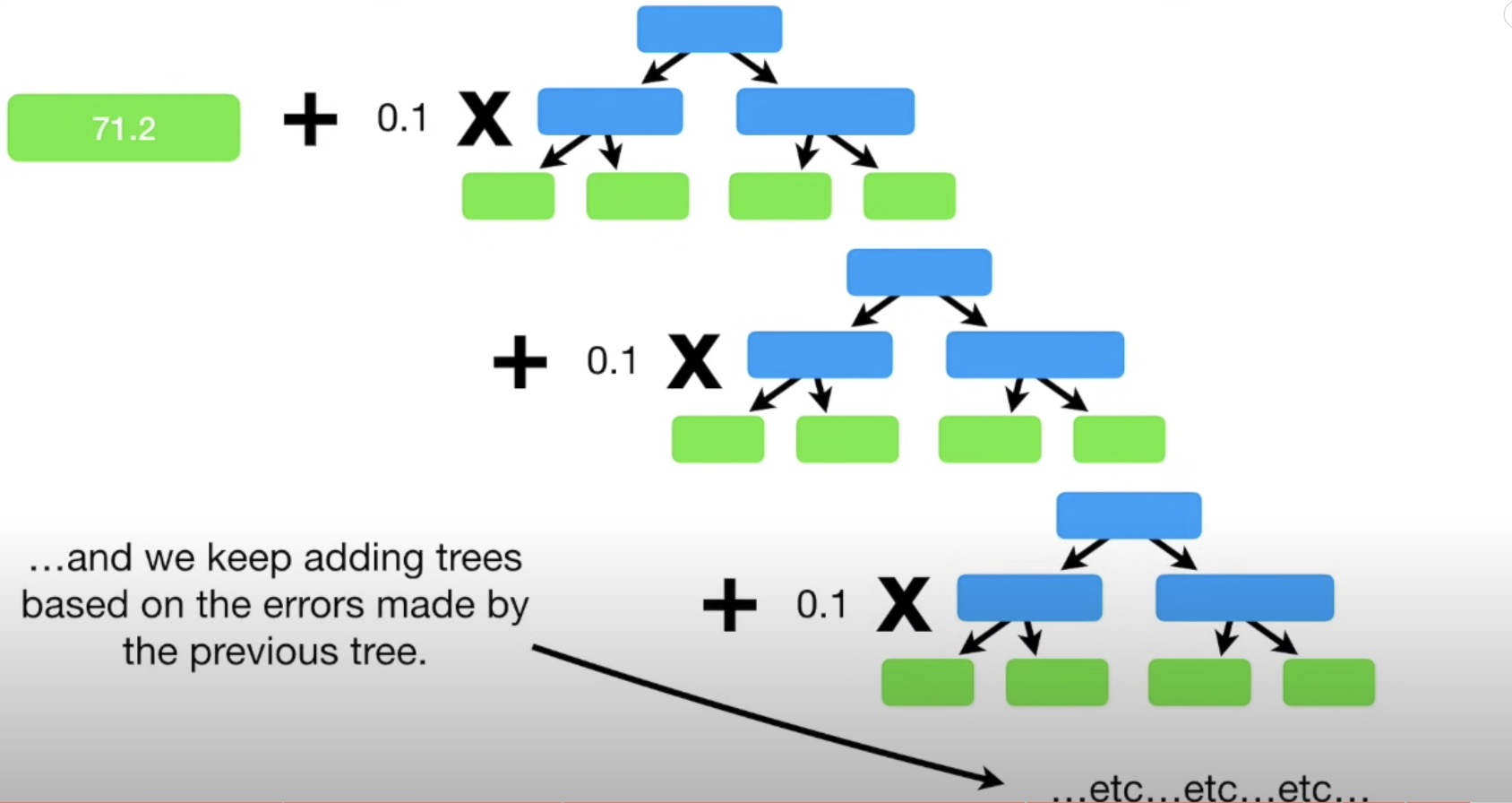

M often = 100 - for classification
log(odds)
set predicted xx
logistic function -> probability
limiting the number of leaves between 8 and 32.
Pseudo residuals means change residual by multiply to make calculate more simple.
the larger log(likelihood),the better prediction.
log(likelihood) multiply -1 as loss function.(argmin)
using 2nd order Taylor Polynomial in (A)
(A)calculate new residuels
(B)create new regression tree
(C)calculate output value
(D)make new prediction (log(odds))
XGBoost(eXtreme Gradient Boost)
- regression
- classification
similarity score
lambda: a Regularization Parameter, which reduce the prediction’s sensitivity to individual observations. prevented overfit. smaller output values for leaves.
gain-gamma -> prune or not
eta (learning rate)
cover min_child_weight -> prune
?predicted drug effectiveness = 0.5
pick optimal outputvalue to make L equation min
regularization penalty by increasing lambda, the optimal outputvalue gets closer to 0.
gradients (g); hessians (h)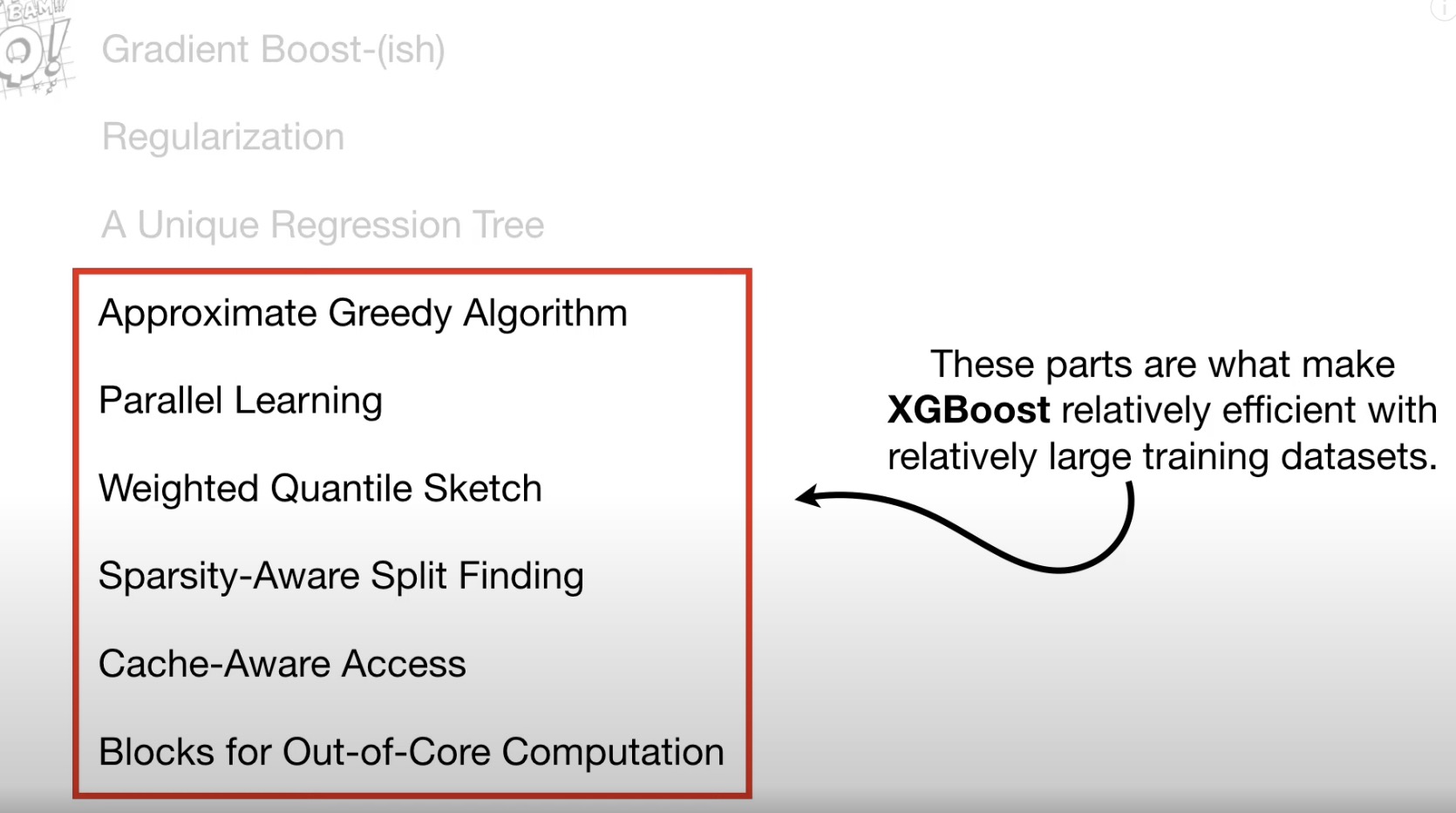
first 3 part is to predict, next is to Optimization for large dataset. - greedy algorithm
quantile (default 33) - sketch algorithms
weighted quantile sketch
weight = previous probability * (1 - previous probability) - Sparsity-Aware Split Fingding
for missing data
Cosine Similarity
Support Vector Machines
Maximal Margin Classifiers
support vector classifier aka soft margin classifiers
above 2 can not handle many cluster of data, so we use support vector machines to find a relatively high dimensional support vector classifier.
hyperplane
Function:
- polynomial kernel
- (a*b + r)^d
r,d varified by cross validation.
- radial kernel aka radial basis function(RBF)kernel: in infinite dimension. behaves like weighted Nearest Neighbor model.
- e ^ (-gamma(a-b)^2)
gamma determined by cross validation.
Taylor Series Expansion

Dot product
when we plug numbers into radial kernel, the value we get is the relationship between the 2 points in infinite-dimensions.
Neural Networks
Backpropagation
Hidden Layers
Activation Function:
- sigmoid e^x/(e^x + 1)
- ReLU (Rectified Linear Unit) max(0,x)
- softplus log(1 + e^x)
initialize weights using a standard normal distribution.(one of many ways)
initialize bias to 0
multi-input
? when input constant output descerete, how to encode output, using one encode?
multi-output: ArgMax(0or1) can not be used for backpropagation.
or SortMax(e^x/e^x+e^y) used for gradient descent because of the derivative not being 0. - calculate deviation of sortmax -> Quotient Rule
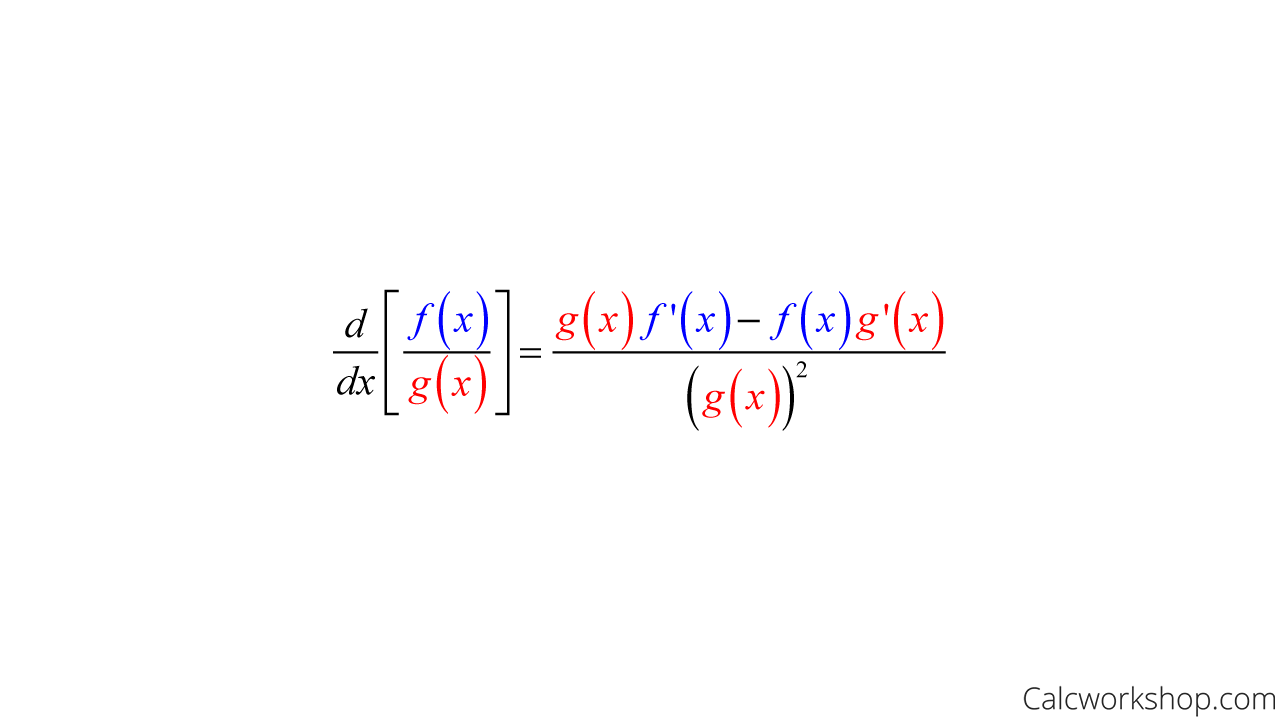
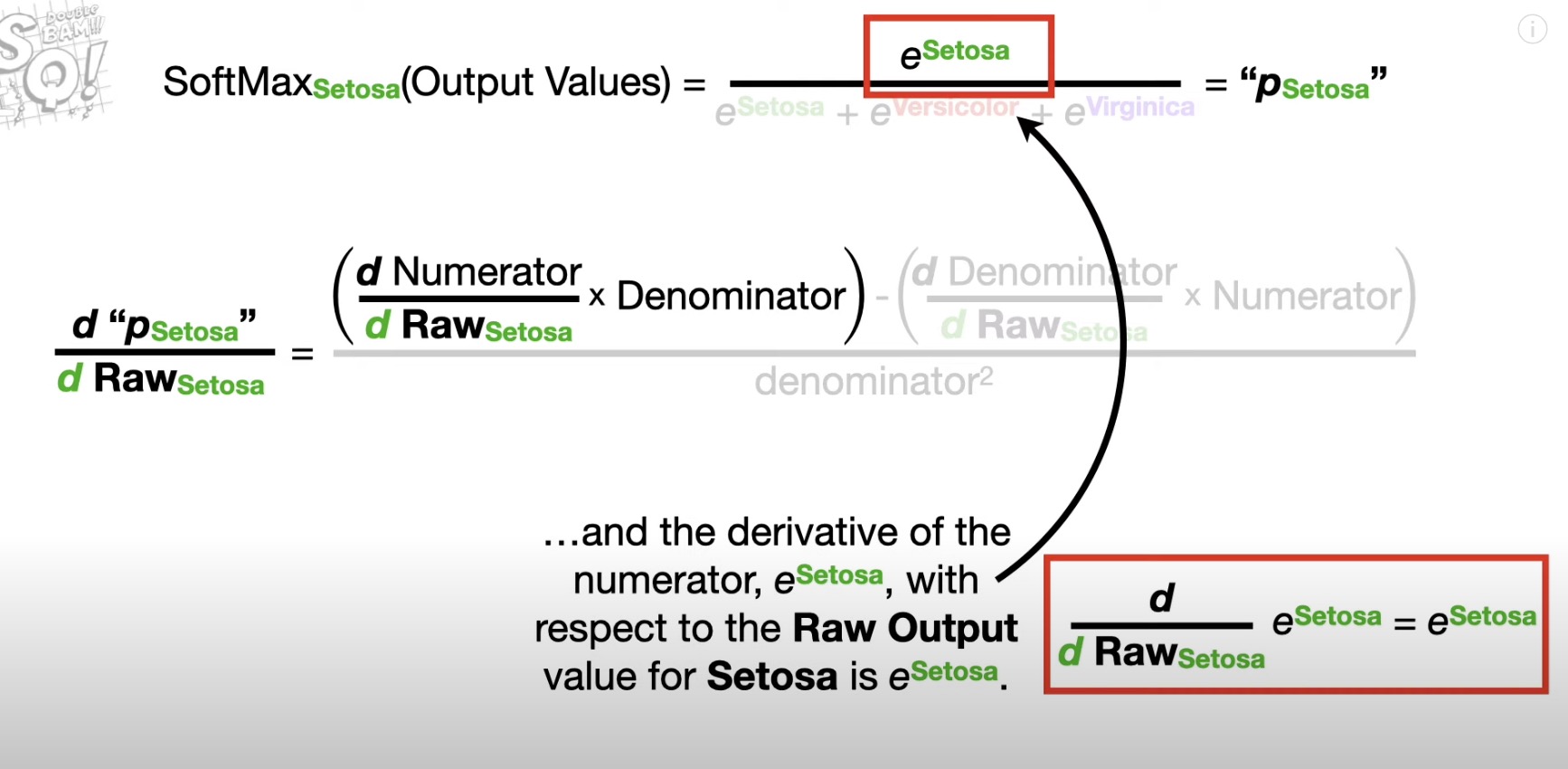
Cross Entropy
each cross entropy- sum (observed * log (predicted))
- predicted = softmax output
- observed = 0/1
Total Cross Entropy, as total error.
why ce not residual: for step size = slope(derivative) * learning rate. used to backpropagation.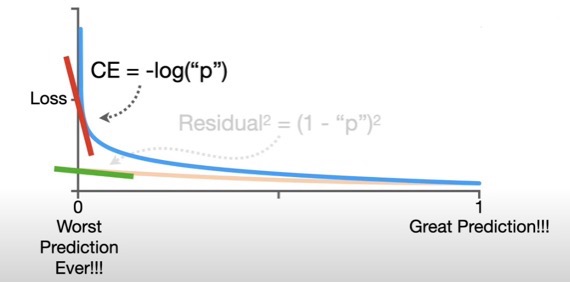
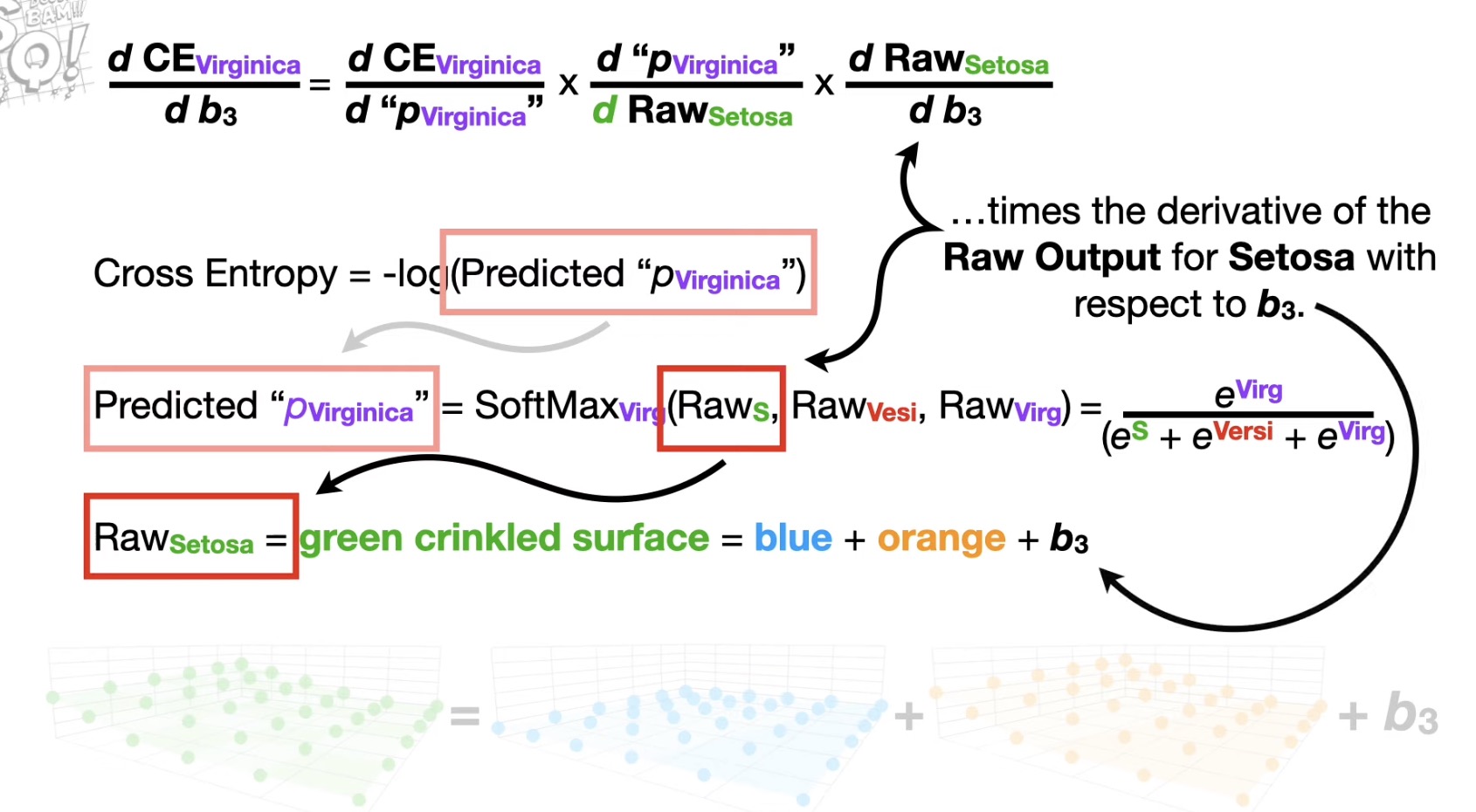
note: when finding minimum total error, even the signal of “p” is the same, we need to use each sample to calculate each ‘p’.
Convolutional Neural Networks(CNNs)
*filter(convolution)=feature map -> ReLu activation function -> max pooling (or average/mean pooling) -> as input node
(?how to determin filter?)
Recurrent Neural Networks(RNNs)
feedback loops
w2>1 ->the exploding gradient problem
w2<1 -> the vanishing problem
so
Long Short-Term Memory(LSTM)
sigmoid activation function (0,1)
tanh activation function (-1,1) e^x - e^-x / e^x + e^-x
forget gate
input gate
output gate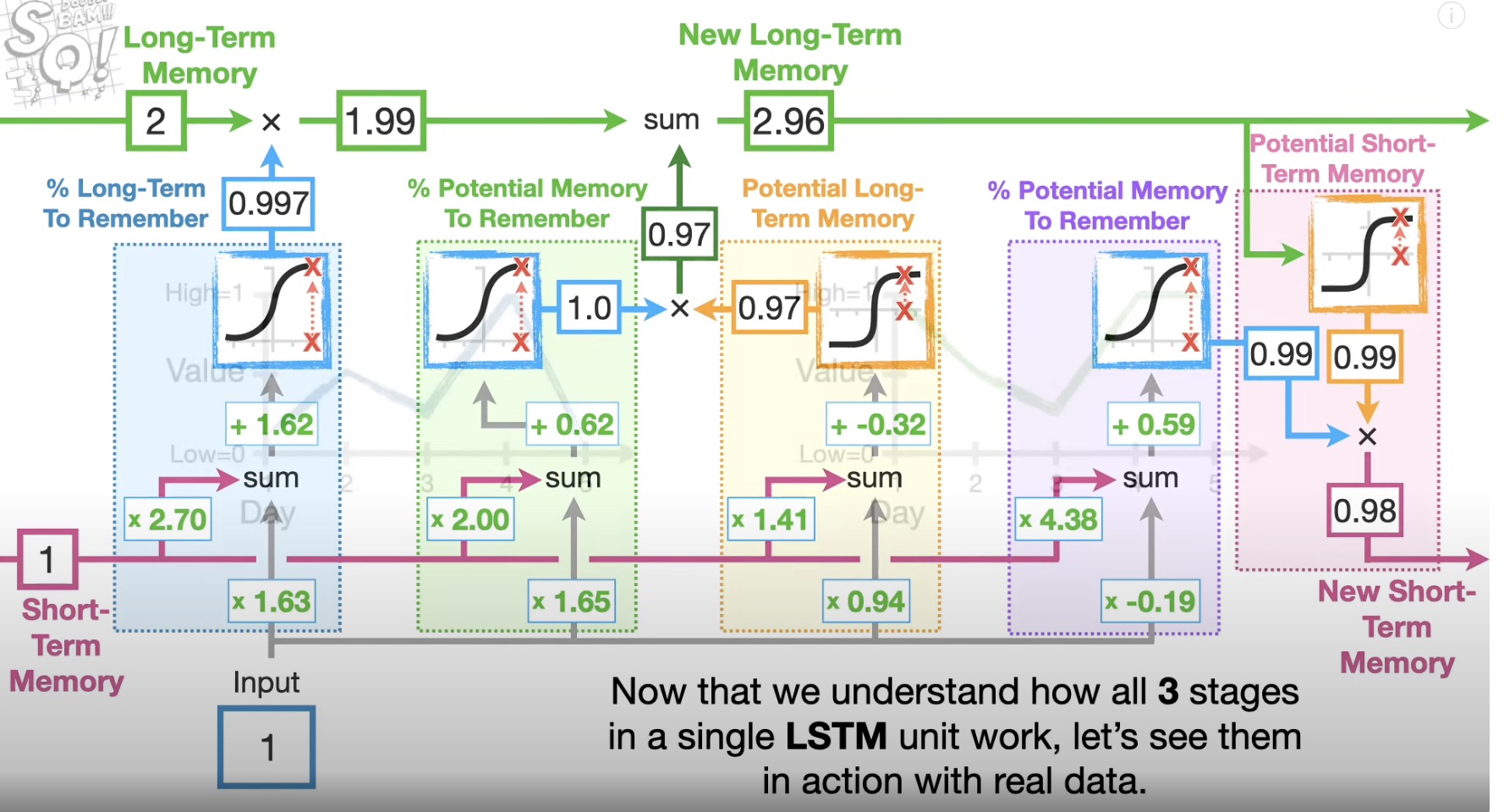
Sequence-to-Sequence(seq2seq) Encoder-Decoder
Tokens
embedding values
cell, layer
context vector
- word embedding(turn word to number)
transformer
- position encoding(encode positions of the words)
? position encoding 1st 2nd x轴位置怎么确定的?
query, key and value
(dot product simularity between query and key) - self-attention(encode the relationship among the words)
8 self-attention cells aka multi-head attention - residual connection(relatively easily and quickly train inparallel)
- encoder-decoder attention(encoder and decoder similarity to determine which word to be translate first)
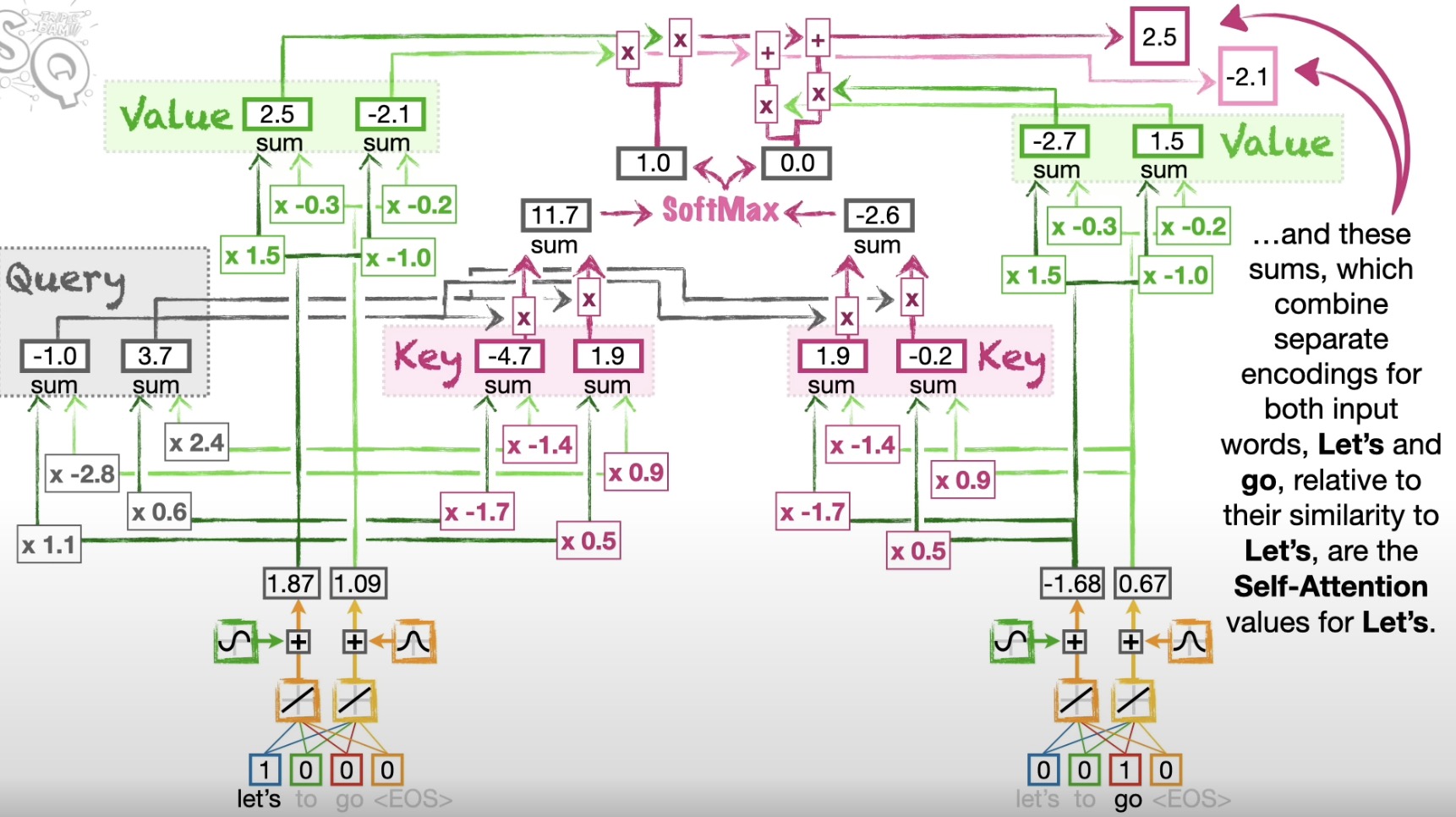
(encoder)
decoder-only transformers
using mask self-attention (gpt 12 self-attention cells) not self-attention
diffenrence:
- only include the ones that came before to determine how each words are related each other.
- in trandition transformer, using self-attention and encoder-decoder-attention (in decoder. During training, this is kindly like mask self-attention and also called it)
n-dimensional Tensor
automatic differentiation